
쯔이's Dev
SELECT 본문
[표현법 1]
SELECT 가져오고 싶은 정보 FROM 테이블명;
[표현법 2]
SELECT (*) 또는 컬럼1, 컬럼2... FROM 테이블명;
- * 은 모든 정보를 의미한다.
EX)
SELECT
*
FROM
employee;EX)
SELECT
emp_name,
emp_no,
phone
FROM
employee;< 컬럼값을 통한 산술연산 >
SELECT절의 컬럼명 작성부분에 산술연산 가능.
- 산술연산 과정중에 NULL데이터가 포함되어 있다면 무조건 결과값은 NULL
- DATE - DATE => 결과는 무조건 일로 표기됨
- 코드실행시 현제시간을 표시하는 상수 : SYSDATE
- DUAL : 오라클에서 제공해주는 가상데이터 테이블
< 컬럼명에 별칭 지정 >
[표현법]
컬럼명 별칭 / 컬럼명 AS 별칭 / 컬럼명 "별칭" / 컬럼명 AS "별칭"
* 컬럼명이 너무 긴 경우
* SELECT절에 함수식이나, 연산식이 사용된 경우 ---> 반드시 별칭이 부여되야한다.
SELECT
emp_name 사원명,
salary AS 급여,
bonus "보너스",
( salary * 12 ) AS "연봉",
( salary + ( salary * bonus ) ) * 12 AS "총 소득"
FROM
employee;<리터럴>
임의로 지정한 문자열(' ')
조회된 결과의 모든 행에 반복적으로 출력
SELECT
emp_id,
emp_name,
salary,
'원' AS "단위"
FROM
employee;
< 연결연산자 : || >
여러 컬럼값들을 마치 하나의 컬럼처럼 연결할 수 있다.
SELECT
emp_name
|| '의 월급은 '
|| salary
|| '원입니다.' AS "급여"
FROM
employee;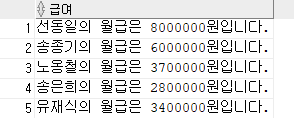
< DISTINCT >
중복제거 - 컬럼에 표시된 값들을 한번씩만 조회하고자 할 때 사용
SELECT DISTINCT
job_code
FROM
employee;< 주의!! >
SELECT DISTINCT JOB_CODE, DISTINCT DEPT_CODE이런 식으로 DISTINCT를 여러번 사용하면 에러가 발생한다.
DISTINCT는 한번만 작성 가능하고 여러 조건을 만족하는 중복제거를 원한다면 아래와 같이 쭉 나열해서 적어주면 된다.
그러면 여러 조건 모두를 만족하는 행을 찾아서 중복을 제거한 값을 보여준다..
SELECT DISTINCT
job_code,
dept_code
< WHERE 절 >
조건식을 적는 부분.
조건식에서도 다양한 연산자 사용이 가능.
>> 비교연산 <<
- >, <, >=, <= : 대소비교
- = : 양쪽이 같다.
- !=, ^=, <> : 양쪽이다르다
[표현법]
SELECT
컬럼,컬럼, 컬럼 연산
FROM
테이블
WHERE
조건;EX) EMPLOYEE에서 부서코드가 'D1'아닌 사원들의 사원명, 급여, 부서코드 조회
SELECT
emp_name,
salary,
dept_code
FROM
employee
WHERE
dept_code != 'D1';* WHRER 절에 어떤 컬럼의 NULL 여부를 비교하고 싶을때는 IS NULL 또는 IS NOT NULL로 해야한다.
CREATE TABLE emp_manager
AS
( SELECT
emp_id,
emp_name,
manager_id
FROM
employee
WHERE
1 = 0
);* WHERE 1 = 0 : 이 조건은 항상 FALSE이므로, 실제로는 데이터가 선택되지 않는다. 이로 인해, 테이블은 데이터 없이 생성된다.
* 이 방식은 테이블 구조만 복사하고, 데이터를 포함하지 않기 때문에 주로 테이블 구조를 복제하고자 할 때 유용합니다.
< and, or 연산자 >
조건을 여러개 연결할 때 사용한다.
[표현법]
조건A AND 조건B -> 조건A, B가 모두 만족하는 값만 참으로 간주한다.
조건A OR 조건B -> 조건A와 조건B중 하나만 만족해도 참으로 간주한다.
< BETWEEN AND >
조건식에 사용되는 구문
몇이상 몇이하인 범위에 대한 조건을 제시할 때 주로 사용하는 연산자(이상, 이하만 가능)
[표현법]
비교대상 컬럼 BETWEEN 하한값 AND 상한값;
< NOT >
논리부정 연산자
컬럼명 앞 또는 BETWEEN앞에 선언 가능
< LIKE >
비교하고자하는 컬럼값이 내가 제시한 특정 패턴에 만족할 경우 조회
[표현법]
비교한 대상컬럼 LIKE '특정패턴' ;
-> 일치하는 것만 가져온다.
특정패턴을 제시할 때 와일드카드라는 특정패턴이 정의되어야한다.
* 와일드카드
1. '%' : 포함문자 검색(0글자 이상 전부 조회)
EX)
비교할 대상 컬럼 LIKE '문자%' : 비교할대상 컬럼값 중에서 해당문자로 시작하는 값들만 가져온다.
비교할 대상 컬럼 LIKE '%문자' : 비교할대상 컬럼값 중에서 해당문자로 끝나는 값들만 가져온다.
비교할 대상 컬럼 LIKE '%문자%' : 비교할대상 컬럼값 중에서 해당문자로 포함된 값 조회
2. '_' : 1글자를 대체하는 검색
비교할 대상 컬럼 LIKE '_문자' : 비교할대상컬럼값 문자 앞에 아무글자나 한글자가 있는 값을 조회
비교할 대상 컬럼 LIKE '문자_' : 비교할대상컬럼값 문자 뒤에 아무글자나 한글자가 있는 값을 조회
비교할 대상 컬럼 LIKE '_문자_' : 비교할대상컬럼값 문자 앞뒤에 아무글자나 한글자가 있는 값을 조회
비교할 대상 컬럼 LIKE '___문자_____' : 내가 원하는 형태로 ' _ ' 를 통해서 문자수를 조절할 수 있다.
EX)
* ESCAPE OPTION
SELECT
emp_id,
emp_name,
email
FROM
employee
WHERE
email LIKE '____%';-- 에러발생< 주의!! >
WHERE EMAIL LIKE '____%'; -> 와일드카드 문자때문에 정상출력이 되지않는다.
와일드카드문자와 일반문자 ' _ ' 를 구분해줘야한다.
데이터값으로 취급하고 싶은 와일드카드 문자 앞에 나만의 탈출문자를 제시해서 탈출시켜주면된다.
[ ESCAPE OPTION을 등록 표현법 ]
WHERE
email LIKE '___/_%' ESCAPE '/';* ESCAPE OPTION은 어떤 기호든 원하는대로 등록 가능하다.
< IN >
WHERE절에서 비교대상 컬럼값이 내가 제시한 목록중에 일치하는 값이 있는지 검사
좀 더 쉽게? WHERE절에서 값1 이거나 값2 이거나 값3인 것들을 모두 조회.
[표현법]
비교대상컬럼 IN ('값1', '값2', '값3')
EX) 부서코드가 D6이거나 D8이거나 D5인 부서원들의 이름, 부서코드, 급여 조회
SELECT
emp_name,
dept_code,
salary
FROM
employee
--WHERE DEPT_CODE = 'D6' OR DEPT_CODE = 'D8' OR DEPT_CODE = 'D5';
WHERE
dept_code IN ( 'D6', 'D8', 'D5' );
< 연산자 우선순위 >
1. 산술연산자
2. 연결연산자
3. 비교연산자
4. IS NULL / LIKE / IN
5. BETWEEN A AND B
6. NOT
7. AND
8. OR
< ORDER BY절 >
가장 마지막 줄에 작성.
실행순서 또한 가장 마지막에 실행한다.
하나만 제시도 가능하고, 여러개도 제시 가능하다.
[표현법]
SELECT
조회할 컬럼...
FROM
조회할 테이블
WHERE
조건식
ORDER BY
정렬기준될 컬럼 | 별칭 | 컬럼순번 [ASC | DESC] [NULLS FIRST | NULLS LAST]* ASC
오름차순(작은 값으로 시작해서 값이 점점 커지는 것)
-> 아무 표시 없이 컬럼명만 써있다면 기본적으로 오름차순을 의미한다. 그러므로 생략가능.
* DESC
내림차순(큰값으로 시작해서 값이 점점 줄어드는 것)
* NULL은 기본적으로 가장 큰값으로 분류해서 정렬한다.
- NULLS FIRST : 정렬하려는 컬럼값에 NULL이 있을 경우 해당데이터 맨 앞에 배치
DESC일때는 기본적으로 NULLS FIRST이다.
- NULLS LAST : 정렬하려는 컬럼값에 NULL이 있을 경우 해당데이터 맨 마지막에 배치
ASC 일때는 기본적으로 NULLS LAST이다.
* 컬럼 순번 : 오라클은 무조건 1부터 시작이다.
EX)
SELECT
emp_name,
salary * 12 AS "연봉"
FROM
employee
--ORDER BY SALARY * 12 DESC;
--ORDER BY 연봉 DESC;
ORDER BY
2 DESC;