FUNCTION(1) - 단일행 함수(문자처리함수)
[ [ 함수 FUNCTION ] ]
* 전달된 컬럼값을 받아서 함수를 실행한 결과를 반환.
* 함수는 중첩사용 가능하다.
ex)
substr(email, 1, instr(email, '@') - 1)
* 단일행 함수 : N개의 값을 읽어들여서 N개의 결과값을 리턴(매행마다 함수실행 결과를 반환)
* 그룹함수 : N개의 값을 읽어들여서 1개의 결과값을 리턴(그룹을 지어서 그룹별로 함수실행 결과를 반환)
< 주의 !! >
SELECT 절에 단일행함수랑 그룹함수를 함께 사용하지 못함
why? 열과 행의 갯수가 다르기 때문(서로 매칭이 안됨)
★ 함수를 사용할 수 있는 위치 ★
SELECT절 / WHERE절 / ORDER BY절 / HAVING절
[ [ 단일행 함수 ] ]
< 문자처리 함수 >
< LENGTH >
[표현법]
LENGTH ( 컬럼명 | '문자열' )
: 해당 문자열의 글자수를 반환
<LENGTHB>
[표현법]
LENGTHB( 컬럼명 | '문자열' )
: 해당 문자열의 바이트 수를 반환
<< 주의!! >>
- '최' '나' 'ㄱ' 같은 한글은 글자당 3BYTE
- 영문자, 숫자, 특수문자 글자당 1BYTE
SELECT
length('오라클'),
lengthb('오라클')
FROM
dual;
SELECT
length('ORACLE'),
lengthb('ORACLE')
FROM
dual;

< INSTR >
문자열로부터 특장 문자의 시작위치를 찾아서 반환
[표현법]
INSTR( 컬럼 | ' 문자열 ', ' 찾고자하는 문자 ', [ ' 찾을 위치의 시작값, 순번 ' ] )
-> 결과는 NUMBER
INSTR( 컬럼 | ' 문자열 ' , ' 찾고자하는 문자 ' )
: 여기까지만 적으면 기본적으로 앞에서부터 시작하여 첫번째 위치를 조회한다.
SELECT
instr('AABAACAABBAA', 'B', 1, 3)
FROM
dual;* 해석 : AABAACAABBAA에서, 'B'를, 앞에서부터 조회하여, 3번째 B의 순번을 찾아라.
* 답 : 10

SELECT
instr('AABAACAABBAA', 'B', -1, 3)
FROM
dual;* 해석 : AABAACAABBAA에서, 'B'를, 뒤에서부터 조회하여, 3번째 B의 순번을 찾아라.
* 답 : 3

SELECT
email,
instr(email, '_', 1, 1),
instr(email, '@')
FROM
employee;* 해석
1. email컬럼에서 ' _ '를 앞에서부터 시작하여 처음나오는 위치의 순번을 조회하라
2. email컬럼에서 @를 앞에서부터 시작하여 처음 나오는 위치의 순번을 조회하라
=> instr(email, '@') - 1 = 아이디의 자릿수
< SUBSTR >
문자열에서 특정 문자열을 추출해서 반환
[표현법]
SUBSTR( STRING, POSITION, [LENGTH] )
* STRING : 컬럼명(문자타입) | '문자열'
* POSITION : 문자열 추출할 시작위치 값(+이면 앞에서부터, -이면 뒤에서부터)
* LENTH : 추출할 문자 갯수(생략하면 끝까지)
SELECT
substr('SHOWMETHEMONEY', - 8, 3)
FROM
dual;
< LPAD / RPAD >
문자열을 조회할 때 통일감있게 조회하고자 할 때 사용
[표현법]
LPAD / RPAD( 컬럼명 ( STRING ), 최종적으로 반환할 문자열의 길이, [ 덧붙이고자하는 문자 ] )
문자열에 덧붙이고자하는 문자를 왼쪽 또는 오른쪽에 붙여서 최종 N길이만큼 문자열을 반환
SELECT
emp_name,
rpad(substr(emp_no, 1, 8), 14, 'x')
--substr(emp_no, 1, 8)|| 'XXXXXX'
FROM
employee;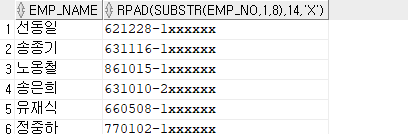
< LTRIM / RTRIM >
문자열에서 특정 문자를 제거한 나머지를 반환. 보통 공백제거 용도로 많이 쓰는 함수이다.
[표현법]
LTRIM / RTRIM ( STRING, [ 제거하고자하는 문자들 ] )
문자열의 왼쪽 혹은 오른쪽에서 제거하고자하는 문자들을 각 방향에서 순서대로 모두 찾아서 제거한 나머지 문자열 반환
<주의!!>
* 두 가지 사례를 살펴보자.
SELECT
rtrim('513543213KH1543542', '0123456789')
FROM
dual;
SELECT
rtrim('513543213KH1543542', '01')
FROM
dual;
위에서는 오른쪽부터 검색을 시작하면 '0123456789' 중에 '2'가 첫 숫자에서 발견되어 점점 왼쪽으로 검색을 시작하다가 '0123456789'에 해당하는 어느것도 발견되지 않는 H에서 멈춘다.
아래쪽에는 1이 지워지지 않았다. 즉 오른쪽에서부터 검색을 시작하여 첫번째로 시작하는 숫자('2')에 우리가 제거하고자 하는 문자('0', '1')중에 하나라도 발견되지 않아서 더이상 진행하지 않고 멈추게 된다.
* 예를 들어 RTRIM(BANANA, NA)을 하면 결과값으로 B가 나온다. 즉, NA를 하나로 인식하는게 아니라 N, A로 인식한다. 제거하고자 하는 문자에 한글자가 아니라 여러글자를 쭉 써도 한글자씩 각각 인식해서 모두 제거한다.
< TRIM >
문자열의 앞 / 뒤 / 양쪽에 있는 지정한 문자들을 제거한 나머지 문자열 반환
< 주의!! >
LTRIM, RTRIM과 마찬가지로 왼쪽이나 오른쪽 양 끝부터 검색을 시작하는데 첫 글자에 제거하고자 하는 문자가 없다면 그 이상 진행하지않고 바로 멈춘다.
[표현법]
TRIM ( [ LEADING | TRAILING | BOTH ] [ 제거하고자하는 문자열 ] FROM 문자열 )
* [제거하고자하는 문자열] 을 안써주면 공백제거를 의미.
* LEADING : 왼쪽부터. 공백 혹은 문자 제거
* TRAILING : 오른쪽부터. 공백 혹은 문자 제거
* BOTH : 양쪽의 공백 or 지정 문자의 반복을 제거.
"LEADING | TRAILING | BOTH" 중에 아무것도 입력하지 않으면 기본적으로 BOTH로 작동.
[표현법]
TRIM ( ' 문자열 ' ) = TRIM ( BOTH FROM 문자열 )
인자로 문자열만 넣으면 문자열 양 옆의 공백과 문자들을 모두 제거.
단, 문자열 중간에 띄어쓰기 같은 공백은 제거되지 않는다.
< LOWER / UPPER / INITCAP >
* LOWER : 다 소문자로 변경한 문자열 반환
* UPPER : 다 대문자로 변경한 문자열 반환
* INITCAP : 띄어쓰기 기준 첫글자마다 대문자로 변경한 문자열 반환
SELECT
initcap('welcome to my kH')
FROM
dual;
[표현법]
* LOWER ( '문자열' )
* UPPER ( '문자열' )
* INITCAP ( '문자열' )
< CONCAT >
문자열 두개 전달받아 하나로 합친 후 반환
[표현법]
CONCAT( STRING1, STRING2 )
SELECT
concat('가나다', 'ABC') -- = STRING1 || STRING2
FROM
dual;
< REPLACE >
특정문자열에서 특정부분을 다른 부분으로 교체
[표현법]
REPLACE( 문자열, 찾을 문자열, 변경할문자열 )
SELECT
email,
replace(email, 'KH.or.kr', 'gmail.com')
FROM
employee;